אז שוב מדריך התיירות שלכם כאן אתכם, לקראת עוד כנס בלאס-וגאס אליו אני אמור להמריא במוצאי שבת הקרובה בלי נדר.
סביב הביקור הקודם בעיר, התרגשתי בעיקר בעניין ה Sphere וכמו שכתבתי לכם, ההתרגשות היתה לגמרי מוצדקת.
הפעם אנחנו מתארחים במלון חדש, Resorts World, שמעבר להיותו מלון סופר דופר מפנק הוא גם אחת התחנות של ה Las Vegas Loop, אחד המיזמים היותר מוזרים של אלון מאסק. בעבר מאסק דיבר על ה Hyper Loop כפתרון אפשרי לתחבורה ציבורית מהירה, היה לו חזון לרשת מנהרות ואקום או יותר נכון תת לחץ בהן ישוגרו הנוסעים בקפסולות יעודיות. זה היה ניסוי מחשבתי מעניין ולאחר שמימן מחקר ראשוני בנושא מאסק שחרר את מסמכי המחקר לציבור על מנת לאפשר תחרות ופיתוח מהיר. היו מספר חברות שניסו להקים מייזם שכזה ביניהן וירג'ין של ריצ'רד ברנסון ולמיטב ידיעתי אף אחד מהמיזמים לא קיים יותר.
בינתיים, כחלק מהתמיכה ברעיון ההיפר-לופ, הקים מאסק את the boring company, משחק מילים על החברה המשעממת וחברת כריית המנהרות וזה מה שהחברה עושה, כורה מנהרות. החברה מוכרת גם להביורים, אבל לא נרחיב על זה הפעם. לעניינו, לאס-וגאס היא מרכס הניסוי של מערכת המנהרות של החברה המצ'עממת, רשת מנהרות בהן ניתן לנסוע בין נקודות עניין בעיר באמצעות צי של רכבי טסלה אוטונומיים, מגיעים לתחנה, נאספים על ידי רכב אוטונומי וטסים מתחת לאדמה אל היעד.
הרשת מאד מצומצמת עדיין, היא מכסה את חלקי ה Las Vegas Convention Center בשלוש תחנות ומקושרת אל Resorts world ושאר הרשת בשלבי תכנון או בניה ראשוניים אבל זה נראה לי מגניב ואני חייב לנסות, אדווח!


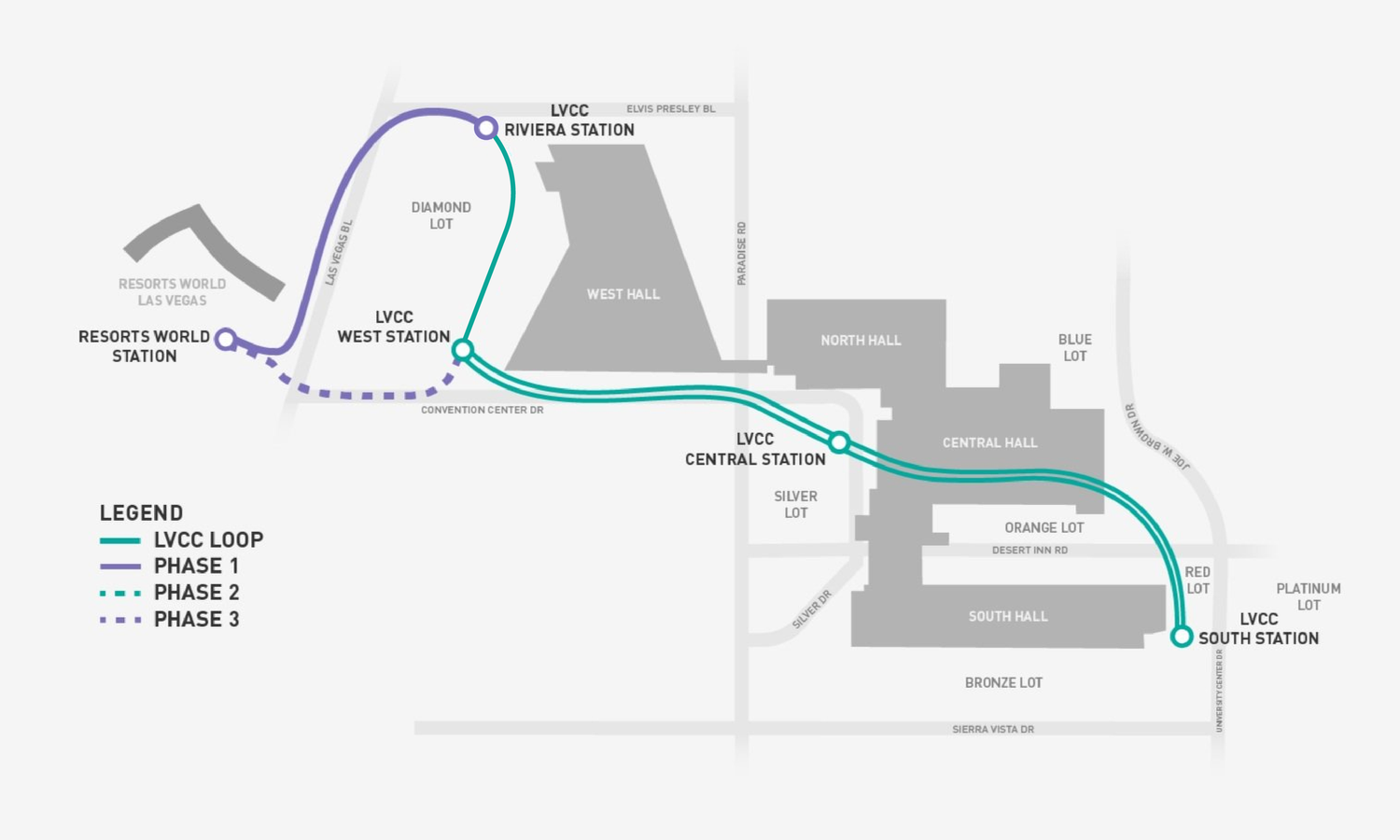
כל התמונות מאתר החברה כמובן.
עברו הרבה שנים כבר מאז ששחררתי קיטור בנושאי Sizing, עכשיו בקריאה חוזרת אני שם לב שדיברתי על "יצרן" למרות שבמרבית הפוסטים שלי אני מדבר על "יצרנית", מעניין אם יש לזה משמעות? כשמתרגמים Vendor זה הגיוני לדבר על יצרן אבל חברה היא יצרנית, נכון?
בכל מקרה אני נדרש בימים האחרונים לחשוב שוב על תהליכי Sizing ברמה הפילוסופית שלהם, לא על הרמה הפרקטית, לא לעשות סייזינג אל ממש לחשוב ולדבר על איך ולמה עושים סייזינג, מה מכלול השיקולים שנכנסים להליך סייזינג וספציפית הנקודה הכי קשה היא לחשוב על סייזינג של 100 אחוז, על איך והאם מערכת יכולה להיות "מושלמת" ולרוץ כל הזמן על 100 ניצולת, להיות מתוכננת "בדיוק" לעומס העבודה המתוכנן עבורה.
התשובה היא, בעיני, לא.
תודה שקראתם וסוף שבוע נעים.
טוב בסדר זו בדיחה שעובדת פחות טוב בכתב אולי, תתעלמו. בכל מקרה התשובה היא כמובן לא והיא לא בגלל הרבה מאד סיבות. הסיבה הראשונה והעיקרית היא שבמרבית המקרים אנחנו פשוט לא יודעים מה הוא אותו עומס עבודה אליו אנחנו נדרשים לתכנן. תחשבו על כל שיחת אפיון שהייתם בה בחיים, כמה שאלות שונות נשארו ללא תשובה בשאלון שלכם, שאלון אמיתי או שאלון תיאורטי ובכל מקרה, שאלון. האם אתם יודעים אם האפליקציה מוטת כמות ליבות או מהירות ליבה? האם היא רגישה יותר לכמות זיכרון או ל מהירות תגובה מהדיסק? כמה מהמידע בדיסק הוא מידע חם וכמה קר? כמה מהר מתקרר המידע שאנחנו מחשביים כמידע קר? האם הקריאה והכתיבה נראו אותו דבר או שאנחנו כותבים רנדומלית וקוראים סדרתית? האם תהליכי ה Meta Data רצים במקביל לתהליכי user io או שמחכים ל off time? האם אנחנו מגדירים את כל ה over head כחלק מהעומס המתוכנן או מעבר אליו? מה לגבי אנומליות? מתקפות?
עכשיו נניח שאנחנו מכירים הכירות אינטימית עם עומס העבודה המתוכנן ויודעים לענות לגביו על כל שאלה אפשרית באופן מושלם, נניח שאנחנו יודעים בדיוק מה הדרישות, האם ניתן בכלל להגיע לאיזון מושלם? בסופו של דבר אנחנו כפופים לאילוצים חיצוניים, כמות המעבדים הנתמכת בשרת הפיזי, כמות הליבות לעומת מהירות הליבות שיצרנית המעבדי בחרה לאפשר, כמות הזיכרון הנתמכת בשרת, לפי חלוקה לגדלי רכיבי הזיכרון שיש, כמות הסלוטים הקיימים על לוח האם, כמות הסלוטים שחובה לאכלס בהתאם לכמות המעבדים וגודל רכיבי הזיכרון, מהירות וגודל הדיסקים שלנו, כמות וסוג כרטיסי הרשת שאפשר לאכלס בשרת, כמות הפורטים על כרטיסי הרשת, איך מסנכרנים את כל אלו באופן מושלם?
עכשיו תכפילו את העומס? עכשיו תכפילו את העומס פי עשר? עכשיו תכפילו את העומס פי 100? מתישהו, at scale, כל הנחות היסוד שעשינו עד עכשיו נשברות ולא תקפות יותר, מה שעובד על המחשב של המפתח לא בהכרח עובד על שרת פרודקשן ומה שעובד על שרת פרודקשן לא בהכרח עובד בקנה מידה של ספקית שירות קטנה ובדרך כלל לא עובד בקנה מידה של ספקית גדולה?
ונניח שצלחנו את כל המכשלות האלו, האם זה בכלל נכון לעשות? האם יש מערכת, לא רק מערכת מחשוב, שמתוכננת לעבוד קבוע בתפוקה מלאה? אני לא מכיר כאלו, אתם מכירים? אפילו ברמת כבלי החשמל, אנחנו מבדילים בין מתח רגעי ומתח קבוע, בין שיא ובין שגרה, בין כמה הכבל מתחמם בשיא וכמה הוא מתחמם בשגרה ויש הבדל בפינוי החום וכו'.
המקומות היחידים שאני מכיר שלוקחים מערכת לקצה ככה, אלו מקומות שמקריבים אמינות לטובת ביצועים. דמיינו מכונית Formula1 למשל, המכונה מתוכננת לעמוד בעומס מקסימלי למשך שעתיים, מתוחזקת על ידי צי של מהנדסים במשך כל השבוע בין המרוצים ומוחלפת כל שנה בדגם חדש יותר, מהיר יותר (לא תמיד מהיר יותר ראו המקרה של מרצדס בזמן האחרון למשל 😊), וזה נכון גם למשל, לפעמים, בסביבות HPC, אנחנו לא מתכננים מערכות כאלו לריצה ארוכת טווח, אנחנו לא צריכים את המערכת הזו לתפקד 100 אחוז במשך עשורים קדימה, אנחנו מקריבים את שרידות המערכת לטובת ביצועים, אנחנו רוצים לקצר את הזמן לקבלת המענה, תוצאת החישוב, שאלת המחקר.

טוב יצא ארוך יותר ממה שחשבתי,
כמו תמיד מאד אשמח לשמוע מה חשבתם (הבת שלי ראתה שאני עובד על הפוסט הזה ושאלה אם אני מפורסם ואמרתי שלא אבל יש לי כמה עוקבים קבועים ואני גאה על כל אחת ואחד!),
בברכת בשורות טובות,
שישובו כל החטופים והחטופות במהרה אמן וכל החיילים והחיילות בריאים ושלמים!
שלכם כרגיל,
ניר מליק







