חיי קהילה – אני ממשיך ללחוץ עליכם
בפוסט הקודם המלצתי לכולכם לחלוק את הידע שלכם עם הקהילה.
אני שמח לחלוק כאן כבוד לחבר שלי, אלי פלורנטל, מנכ"ל חברת פלורמה, שזכה השבוע בפרס על 45 שנות תרומה לתעשיית הפלסטיקה בישראל! כבוד לאיש חם וחכם שחולק את הידע שלו ומסייע לכל התחום שלו לצמוח ולהתפתח!

השבוע גיליתי גם שידידי היקר, נתנאל בן שושן, מנהל תחום מיקרוסופט אצלנו בחברת We Ankor הוא אחד מתשעת החברים המכובדים בקהילה המיוחדת של VMware vExpert בישראל. זה אומר שגם הוא ממשיך את המסורת שהתחיל כ Microsoft MVP ומשקיע זמן ואנרגיה כדי לחלוק את הידע הרב שצבר עם קהילת ה IT שסביבנו.
VMware vRNI
נתנאל ואני השתתפנו בכנס שערכנו השבוע עבור אחד הלקוחות הגדולים שלנו, נתנאל דיבר על החידושים ב vSphere 6.5 ואני דיברתי על השימושים הנפוצים לפתרון VMware NSX.
באותו אירוע דיבר גם אבי יושי, מהנדס מערכות בכיר ב VMware ישראל, שהציג את פתרון ה VMware vRNI או בשמו המלא, vRealize Network Insight. כלי מאד חזק לוויזואליזציה של התעבורה בחדר השרתים. אחד האתגרים הנפוצים בבניית סט חוקי אבטחת מידע בסביבות מורכבות הוא מיפוי ומעקב אחר הגורמים השונים, לאיזה שרת מותר לתקשר עם איזה בסיס נתונים, איזה שירות Web מנסה להגיע אל איזה כרטיס רשת וכדומה. ככל שהסביבה גדולה ומורכבת יותר כך האתגר הזה מורכב יותר. תשתיות וירטואליזציה ותשתיות Software Defined מוסיפות נדבך של מורכבות כי חלק מהתעבורה ולפעמים חלק ניכר מהתעבורה כלל לא מגיע אל חומות האש הארגוניות או מתגי ה Layer 3 שלנו ולכן התעבורה אינה גלויה לתהליכי NetFlow.
vRNI מספק ממשק פשוט, אינטואיטיבי ויפה מאד ויזואלית למיפוי התעבורה והצגתה באופן קל וברור להבנה. זו יכולת נחמדה אבל עוצמתו העיקרית של הכלי תמונה ביכולת להפוך את הגילוי להמלצה ישימה כלומר, לאחר תהליך מיפוי והמחשת התעבורה מספק הכלי המלצות לבניה של סט חוקי התעבורה והאבטחה.
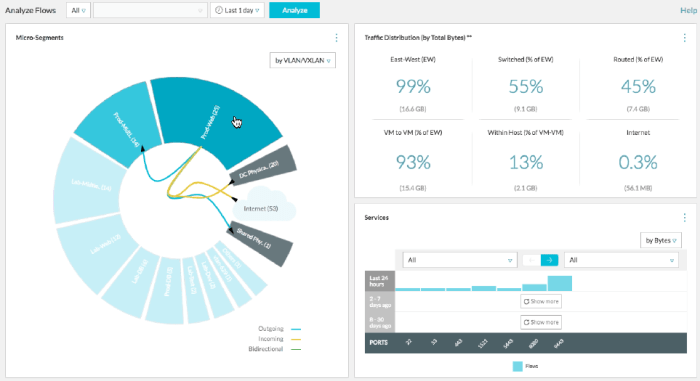
תצלום המסך הבא למשל מראה לנו תעבורה בין שני שרתים וירטואליים כאשר נוח לגלות על איזה Host הם יושבים, דרך אילו VLAN'ים התעבורה עוברת ואת רכיבי התקשורת הפיזיים המעורבים.

בתצלום הזה אנו רואים מיפוי של שירות web ספציפי לניתוח סוגי התעבורה השונים שלו
היום אירוע שני אירועי התפרצות לבתים במושב בו אני גר ובדיון בקבוצת הווטסאפ שלנו הזכירו כי "קו המגע לעולם ייפרץ". אחד הקוים המנחים ביישום מיקרו-סגמנטציה, ה use case הכי נפוץ של NSX, הוא שבתצורה זו קל יותר לגלות פריצה ולהכיל אותה משהתרחשה. ללא מיקרו-סגמנטציה, בעולם של VLAN'ים גדולים, מרגע שנפרץ משאב אחד, התנועה האופקית בתוך שכבת האבטחה שלו קלה יחסית ולפעמים גם נשארת חבויה ולכן השילוב של שני הכלים, vRNI+NSX יכול לייצר פתרון אבטחת מידע מאד אפקטיבי.
Cisco Hyper-Flex
בנושא אחר, יצא לי לשחק לאחרונה קצת עם פתרון ה Hype-Flex של Cisco. פתרונות ה hyper-Converged הם נושא מאד חם בתקופה האחרונה ובטח יצא לכם לשמוע על הרכישה המשמעותית של HPE את SimpliVity.
הפתרון מבוסס שרתי Cisco בתצורת Rack ככה שכבר אנחנו יודעים שמבחינת החומרה אנחנו מקבלים פתרון מאד איכותי. כל השרתים מקושרים ל Cisco UCS FI סטנדרטי אז אין עקומת לימוד גדולה מדי לניהול תשתית החומרה וכשאני אני מתכוון שאין עקומת לימוד גדולה מדי אני מתכוון שגם ככה ממשק הניהול של UCS הוא ממשק מעולה ונוח לשימוש. אגב, היות ומדובר באותו FI, ניתן לנהל גם סביבת Hyper-Flex וגם סביבת UCS רגילה באמצעות אותם מתגי ניהול, זה די נוח ללקוחות קיימים וכן מאפשר את הגמישות לקשר אל ה Hyper-Flex Cluster גם שרתי Compute בלבד מתוך מערך ה UCS Blade או שרתי UCS Rack אחרים המקושרים אל ה FI. אין צורך ברישוי Hyper-Flex עבור שרתי Compute only.
הקלאסטר כולל מינימום של 3 שרתים ועל כל שרת מותקן Storage Controller האחראי לכלל פעילות ה IO מול הדיסקים המקומיים בשרתים. מערכת ה"אחסון" משתמש בטופולוגית log structured שמאפשרת כתיבה ל buffer, ביצוע inline dedup/compression והורדה סיקוונסיאלית של המידע הנכתב אל הדיסקים. יכולות אלו משמעותיות מבחינת ביצועים בתצורות היברידיות ומבחינת flash cell wear leveling בתצורות all flash. תהליך ה stripe מתבצע על כלל הדיסקים המוקצים לקלאסטר על מנת לרתום את כל הספינדלים לתהליכי ה IOps. כלל ה Storage controllers נגישים לפעילות IOps ב pNFS לשרתי ה Compute כדי לא ליצור צוואר בקבוק בגישה אל המידע. תהליכי ה Snap Shot הם תהליכי redirect on write זריזים ויעילים כמקובל בימינו.
מתגי ה FI הם כאמור מתגי FI סטנדרטיים. היות וניתן לקשר אל מתגי FI מערכי אחסון ניתן במידת הצורך לחשוף לשרתים הוירטואליים החיים על ה Hyper-Flex גם LUN ממערכת אחסון חיצוני. לא יודע אם זו תהיה תצורה נפוצה אבל נחמד שיש את הגמישות לעשות את זה הרי זו אחת נקודות הביקורת נגד פתרונות HCI, העובדה שחלקם מאד גמישים רק כל עוד נשארים בתוך מסגרת פתרון ה HCI.
החשודים המידיים לשימוש בפתרונות HCI הם סביבות VDI שם הגידול הליניארי ברור ומובהק, סביבות מעבדה שצריכות גמישות תפעולית רבה ולאחרונה יש טרנד מעניין של שימוש ב HCI ליישום של קלאסטר ניהול נפרד מקלאסטר הייצור.
נקודה אחרונה בעניין ה Cisco Hyper-Flex – לעובדי החברה ולשותפים יש גישה גם לכלי סייזינג רשמי של היצרן וזאת בניגוד לחלק מהמתחרים שעובדים עם קבצי אקסל או בשיטת "דבר איתי אני אעזור לך", זה יתרון מאד משמעותי באפיון פתרון שכל מהותו לספק גמישות בלי להתפשר על ביצועים.

The Phoenix Project
בפוסט הקודם דיברתי גם על the phoenix project והבטחתי לחזור ולהתייחס אליו. אז מה למדתי?
ראשית, הגיבור שלנו, ביל, למוד להפריד בין ארבעה סוגים של עבודה. הסוג הראשון של העבודה הוא פרויקטים עיסקיים כלומר פרוייקטים שהתוצר שלהם אמור להביא לתועלת עיסקית לארגון. הסוג השני הוא פרויקטים פנימיים של IT, פרוייקטים שצריך לבצע כמו שדרוג מערכת אחסון או הטמעה של חומת אש חדשה. צריך לבצע אותם אבל הם לא בהכרח נמדדים כמביאים תועלת עיסקית. הסוג השלישי של עבודה הוא שינויים, כל אותן פעולות שאנחנו מבצעים כמו עדכוני קושחה, תלאי אבטחת מידע וכו'. שינויים אלו אינם פרוייקטים גדולים מורכבים או ארוכי טווח אבל הם דורשים משאבים, תשומת לב ויכולת ניהול סיכונים. הסוג האחרון הוא הסוג המסוכן ביותר, עבודה לא מתוכננת או עבודה דחופה. זה הסוג המסוכן ביותר כי הוא שואב משאבים רבים, לפעמים עד כדי כך שסוגי העבודה האחרים נעצרים לחלוטין, הוא בדרך כלל מתחיל כבר במצב לחץ ובהלה ופעמים רבות יוצר בעצמו נזקים אגביים, החל מדחיית מועדי סיום של עבודות אחרות וכלה בהחמרת המצב, השבתות של תהליכים עיסקיים וכדומה.
למה זה חשוב להפריד בין סוגי העבודה השונים? כי זיהוי זה מאפשר לנו למפות נכון את המשאבים הנדרשים לטיפול בכל המשימות שלנו, לתעדף אותן נכון ולמנוע מהמשאבים שלנו לזלוג למשימות פחות חשובות או פחות דחופות.
הדבר השני שביל שלנו לומד, זה לזהות את המשאב העיקרי שלו בתהליכי העבודה. בביקור באולם ייצור, המנטור של ביל, אריק, מראה לו את אחד התנורים על רצפת המפעל. זה צוואר הבקבוק בתהליך הייצור באותו מפעל. כל פעולה לשיפור תהליכים לפני או אחרי התנור לא תספק שינוי מהותי בתפוקת המפעל ולכן תהליכי השיפור העיקריים צריכים להתרכז בתפוקת התנור עצמו, אם התנור לא מנוצל כראוי שום דבר אחר במפעל לא יעמוד בלוחות הזמנים שנקבעו לתהליכי הייצור השונים. במחלקה שתחת אחריותו של ביל, תנור הייצור הוא ברנט, המהנדס הבכיר והמנוסה ביותר שידו בכל ויד כל בו. ברנט הוא הנכס הכי משמעותי ב"רצפת הייצור" של ה IT בארגון בו ביל עובד, תהליכים רבים, מכל ארבעת סוגי העבודה דורשים מעורבות של ברנט ולכן למעשה הוא לא מספיק לעשות כלום, הכל עובר דרכו והכל דחוף וחשוב ולכן שום דבר לא באמת מקבל יחס של דחוף וחשוב אלא רק את ה best effort של ברנט.
דבר נוסף שביל אנחנו לומדים בתהליך הוא השליטה בכמות העבודה, איך מחליטים איזו עבודה אנחנו מוכנים לקבל על עצמנו? שוב במתודה שביל לומד מניהול רצפות הייצור, אם מקבלים את כל העבודות שזורקים לכיוון רצפת הייצור ומקבלים אותן ללא סינון או סידור, תורי העבודה מתארכים, אין דרך יעילה לאזן את המשאבים (חומרי הגלם, המכונות, העובדים, אותו תנור קריטי שהזכרתי) ולכן כל העבודות, כל המשימות כולן מתעכבות, ככל שעומס העבודה יגבר כך למעשה יגברו רק האיחורים התיקונים והמשימות שיש לבצע שוב מחדש כי לא בוצעו כראוי בפעם הראשונה. אריק מספר כאן לביל על תיאוריות ייצור כמו lean, TQM ועל the theory of constraints ומראה שאם יש משאב קריטי שמנוצל במאה אחוז, למעשה הוא לא ממש יעיל כי הוא לא מסוגל לקבל שום עבודה חדשה, ככל שיש לנו יותר משימות פתוחות או יותר work-in-progress כך יתארך הזמן הנדרש להשלים כל משימה, להשלים כל WIP. באחד הפרקים בספר, שוב מגלים שיש עיקוב מאד גדול בפרויקט הכי חשוב של החברה, פרויקט פיניקס. תחקיר קצר מעלה שברנט אמר על משימה שקיבל שהיא תיקח רק 45 דקות אבל בפועל לקח לו מעל שבוע להשלים אותה. לאחר כמה ימים ארוכים של המתנה ברנט התפנה לאותה משימה שאכן לקחה בערך 45 דקות לביצוע. זמן העבודה בפועל לקח 45 דקות אבל משך הזמן המלאה לביצוע המשימה צריך לכלול את זמן ההמתנה להתפנות המשאב כלומר, שבוע + 45 דקות.
הדבר האחרון שאני רוצה לדבר עליו מתוך הספר הוא חשיבות התרגול. ביל, כמו גם אריק המנטור וכמו מנכל החברה, סטיב, שירת בעברו בצבא ארצות הברית (הנחתים ליתר דיוק) ולכן קל להם להבין את החשיבות של תרגול חוזר והטמעת הרגלים לפיתוח "זיכרון שריר". גם בתוך ארגון ה IT שבניהולו של ביל מטמיעים את ההבנה הזו וחוזרים על תרגול מהסוג שנקרא בצבא "תרגיל מפורק" כלומר תרגיל שמתבצע ברובו בדיבור: אם יקרה ככה אז אני אעשה את הפעולה הזו ואדווח אליך דרך מכשיר הקשר הזה, אתה תבצע את הפעולות האלו ותדווח למישהו אחר דרך מכשיר הקשר ההוא. בנקודה מסויימת אפילו מדברים בספר על הזרקה של כשלים אמיתיים לתוך המערכת רק כדי לשמור אותה מתורגלת ומיומנת בהתמודדות עם תקלות תוך כדי ריצה, זו מתודה שלא מתאימה לכל אחד כמובן אבל הרעיון מעניין מאד לדעתי, מערכת שלא משתפרת באופן תמידי היא מערכת דועכת.
לימון כבוש
הפוסט הפעם ארוך מהרגיל אז למי ששרד עד לכאן מגיע פרס ולכן אחלוק אתכם מתכון ללימון כבוש:
שוטפים היטב את הלימונים – עבור צנצנת בגודל כמו של צנצנת נס-קפה נדרשים כשישה לימונים יפים
חוצים את הלימונים לאורך ואז פורסים לרוחב לפרוסות.

מסדרים יפה את הפרוסות בצנצנת במסודר, אחרי כל לימון שמסדרים מפזרים כפית אחת של מלח גס ובאמצעות בקבוק או צנצנת דקה וארוכה מועכים קצת את פרוסות הלימון.
לגיוון ניתן לפזר גם טיפה סומק או אפילו שבבי פלפל חריף.
לאחר שהצנצנת מלאה שופכים מעל הכל קצת מיץ לימון וסוגרים את המכסה כאשר מתחתיו כלי קטן בעל תחתית שטוחה כדי לשמור את הלימונים תחת הנוזל.

שומרים מחוץ למקרר שלושה ימים ואוכלים בתיאבון. מה שלא נאכל מיד נשמר במקרר לתקופה מאד ארוכה.

כמו תמיד אשמח לשמוע מה דעתכם, אל תהססו!
שלכם,
ניר מליק